How to Write a Zotero Translator:
A Practical Beginners Guide for Humanists
By: Adam Crymble


Chapter 4: The DOM & HTML
This Chapter
- What is the DOM?
- Understanding HTML Structure
- Why is the DOM Important to you?
- Practice
- What you should understand before moving on
- Further Reading
Note: Words appearing between < > are HTML elements.
Words that appear between <!–– and ––> are HTML comments, intended for human readers, ignored by the browser.
HTML comments do not tell your browser to do anything, but can be used to provide valuable information to anyone reading your code. If you do not recognize these markup structures, or find it difficult to follow this chapter, please take the W3Schools HTML tutorial before continuing.
What is the DOM?
DOM stands for "Document Object Model."
It is not so much a thing as a way of describing how web pages are structured.
Most people think of a web page much the same way as they think of a newspaper spread: there are words, pictures and headlines on various parts of the page. As far as we can tell, white space appears where nothing else has been placed. However, this is not how websites actually work.
Web pages are actually comprised of a series of nodes. These nodes are organized in a particular hierarchy, as defined by the person who wrote the web page, according to how they decided they wanted the page to function. But before we discuss that further, let's take a look at what a web page really is.
Understanding HTML structure
If you've ever written a basic web page, you know that it is really just an HTML document. These documents contain the page's content — the words, links, images — as well as a series of tags that help your browser understand at what it is looking.
If you've never written a website, go up to your "View" menu and click on "Page Source." A new window will pop up with what is called "source code." This is what your browser interprets. The result of this interpretation is what you see in your browser when you go to the website.
"Don't worry if you can't understand most of the things you see in the source code; most major commercial organizations go out of their way to make the source code of their websites confusing so that people cannot copy their style and format.
You certainly don't need to understand everything about web pages to write a Zotero translator. However, you will have to have a general understanding of how HTML documents are structured.
Most newer websites contain many languages and markup styles in a typical page source. These include but are not limited to JavaScript, Java, PhP, Flash, CSS and XML.
HTML will always appear between two sets of angle brackets < >. Looking for these will often make it easier for you to distinguish HTML from other markups and code. Many browsers, including Firefox, will colour code the source for you to make your job even easier. At this point, we are only interested in looking at the HTML bits, which means you can ignore everything else.
For the most part, the tags we are interested in start with: <div>, <span>, <table>, <tr>, <td>, <ul>, <li>, <p>, <img>, <a href>, <h1>, <h2>, <h3>, <h4>, etc.
Every HTML document will contain the same basic structure
Example 4.1
<html>
<head>
<!––metadata. Generally not visible when visiting a webpage (except title). ––>
</head>
<body>
<!––the content of the page. Generally is visible. ––>
</body>
</html>
Example 4.1 is a fully functional — though boring — HTML document, which would display a blank white page.
Notice that HTML tags always come in pairs. One to tell the browser, <this is beginning> and one to say </this is finished>. What appears between that set of tags is the content of that set. In the example above, the content of the <head> and <body> tags are just HTML comments that a human reader could see when looking at the source code.
Each pair of tags represents one node known as an "element." The <html> node — part of every HTML document (see the first and last lines of the example) — is also known as the root node which is the first node in the "document." All other nodes spring forth from this root node.
The example above consists of three element nodes: an <html> node, a <head> node and a <body> node.
Take note that in our standard HTML document, all the tags are properly "nested." This means that if a node overlaps another node it is always completely contained within that node. You will never see a proper HTML document with a structure like this:
Example 4.2
<html>
<head>
<body>
</head>
</body>
</html>
The tags in Example 4.2 are not properly nested.
In Example 4.1, notice the <head> node and <body> node are both wholly contained within the <html> node (the <html> and </html> tags start before and close after both <head> and <body> have closed). The <head> and <body> nodes do not intersect with one another.
Programmers have jargon to describe the relationships between these nodes:
| Parent: | <html> is the parent of <head> and <body> |
| Child: | <head> and <body> are the children of <html> |
| Sibling: | <head> and <body> are siblings. |
| Grandchild: | This example doesn't have any grandchildren, but if we were to add another node (a link for example), to either <head> or <body>, that node would be the grandchild of <html>. |
A node can have an infinite number of child nodes, but only ever comes from one parent. Most pages are much more complicated than a blank white page. It is not uncommon for an HTML document to contain dozens or perhaps hundreds of element nodes.
This network of relationships between nodes in an HTML document is the DOM.
Why is the DOM important to you?
The DOM is how you give your computer directions to find a particular piece of information in an HTML document. Computers can't jump to a desired element node the way our eyes can jump to a particular point on the screen. They need to crawl to that node, visiting all the connected parent nodes along the way, starting at the root.
Here is a simple Table in an HTML document on which to practice.
Example 4.3
<html>
<head>
</head>
<body>
<table>
<tbody>
<tr>
<td>Precipitation</td>
<td>Temperature</td>
</tr>
<tr>
<td>Rain</td>
<td>Cool</td>
</tr>
</tbody>
</table>
</body>
</html>
Note: On a well—written web page, you can get some clues as to what is a child of what by looking at the indentation of the lines of code. For each indent, you have undergone another branching of the tree and therefore have a new child node. Unfortunately, not everyone writes clean, easy to read HTML like this. If the website you are translating does not, don't worry, there's a way to work around it that you'll learn about in the next chapter.
Now there are 11 nodes.
Example 4.4
- <html>
- <head>
- <body>
- <table>
- <tbody>
- <tr>
- <tr>
- <td>
- <td>
- <td>
- <td>
Note: <tr> stands for "Table Row" and <td> for "Table Data." This is standard HTML.
Your browser displays this HTML document as
Example 4.5
| Precipitation | Temperature |
| Rain | Cool |
If you wanted to tell someone where to find "Cool" in this table, you would probably say, "Look in the bottom right corner."
To give our computer instructions to find "Cool" you have to tell it where to find that particular node.
Example 4.6
<html> → <body> → <table> → <tbody> → 2nd <tr> → 2nd <td>
If you want to visualize this, a tree structure is perhaps easiest to understand.
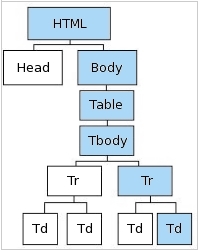
Fig 4.1: The DOM as a Tree
In plain English, you're looking for the second table data, contained in the second table row, of the table body, of the table, which is part of the body, which in turn is part of the document.
Note: Notice that "Cool" is not the 4th <td> node. Rather, it is the 2nd <td> of the 2nd <tr>. This distinction will become important later (and will be addressed in Chapter 5).
A quick note on aunts and uncles
We have already learned a little family jargon to help us understand the DOM. We know that <tbody> is the grandparent of <td>. We know that <head> and <body> are siblings. But, not all nodes are related. In the DOM, aunts and uncles count for nothing.
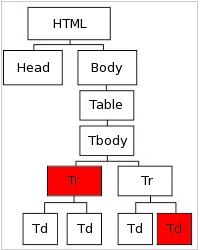
Fig 4.2: Aunts & Uncles in the DOM
These two nodes are essentially unrelated. You cannot tell the computer to get the "Cool" cell of the table by traveling through the first <tr> node. A legitimate path to "Cool" can only contain the first <tr> node if it also contains the second <tr> — the parent of "Cool."
For Example:
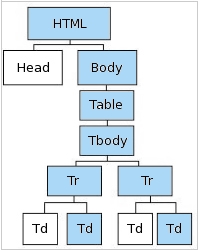
Fig 4.3: DOM Tree w. Multiple Results
Example 4.7
<html> → <body> → <table> → <tbody> → <tr> → 2nd <td>
Notice we have simply been less specific about what we were looking for (removed the 2nd in front of <tr>), but we now have created a path that directs us to both "Temperature" and "Cool." This may or may not be desirable as you will see in Chapter 5.
Nodes need not be tables. Any HTML element is a node. Only certain kinds of nodes contain information that is displayed on web pages:
| <h1> | A headline tag. Generally appears as big and bold (though that can be changed. There are also smaller renditions for less important headlines: <h2><h3><h4>, etc. |
| <p> | Paragraph tag. Usually contains text, but can also include images and links. |
| <img> | Image tag. A link to the image, which your browser finds so that it can display the actual image |
| <a href> | Link tag. Allows designers to embed a link in a word or series of words |
| <li> | List item tag. Appears as an item or series of items, often accompanied by bullets. |
| <td> | Table data tag. The content found in a table like the one we practiced on earlier. |
The rest of the nodes serve other purposes, often related to how or where a displayed node will appear on the page. Some examples are:
| <div> | Division tag. Used to separate code into manageable chunks that can be moved around and formatted in a certain way. |
| <span> | Span tag. Used to change the look of smaller pieces of code than <div> would be used for. A few words, for example. |
| <ul> | Unordered List. Used in conjunction with a <li> tag. |
| <table> | Table tag. Defines the opening of a table. |
| <tr> | Table row tag. Defines a new line in a table. |
Practice
If you feel confident that you understand the DOM and how to find various element nodes in it, you can skip ahead to the next section. If you would like some more practice, here is a sample HTML document and some questions through which to work.
Example 4.8
<html>
<head>
</head>
<body>
<table>
<tbody>
<tr>
<td>Day</td>
<td>Month</td>
</tr>
<tr>
<td>Wednesday</td>
<td>September</td>
</tr>
</tbody>
</table>
<a href="http://niche-canada.org">NiCHE Homepage</a>
<table>
<tbody>
<tr>
<td>Title</td>
<td>Author</td>
<td>Place</td>
<td>Publisher</td>
<td><img src="http://nicheLogo.jpg"></td>
</tr>
<tr>
<td>NiCHE Homepage</td>
<td>Adam Crymble</td>
<td>London, ON</td>
<td>NiCHE</td>
<td>2009</td>
</tr>
<tr>
<td><a href="http://www.Zotero.org">Zotero</a></td>
<td><img src="http://AdamPhoto.jpg"></td>
<td><img src="http://ZoteroLogo.jpg"></td>
<td><a href="http://niche-canada.org">NiCHE</a></td>
<td>Copyright Crymble<td>
</tr>
</tbody>
</table>
</body>
</html>
- How many element nodes are there in this example?
- How many children does the <body> node have?
- How many great—great—grandchildren does the <body> node have?
- Describe a path to find the link to the Home Page
- Describe the path to tell the computer how to find the element node containing the text "Adam Crymble"
- Describe one path to find "Day" and "Wednesday."
- Describe one path that will lead to all the data contained in the 2nd <table>.
- Describe a path that will lead to all the images contained in the 2nd <table>.
- Describe a path that will lead to only the 2nd and 3rd images in the <table>.
What you should understand before moving on
- At this point, you should understand the fundamentals of HTML documents and the HTML tags that make up those documents.
- Even if you cannot read the source code of a complicated website, you should understand the basic components, including <html>, <head>, and <body> as well as the common HTML elements used to output information to users: tables, text, images and links.
- You should understand nodes and the relationships that they have with other nodes within an HTML document.
- You should be able to explain in plain English how to find any element node in a basic HTML document using the DOM.
- You might read in other texts that you should "Access the DOM." For your purposes, you can substitute "Use an XPath" for these words. You'll learn how to do this in Chapter 5 and Chapter 11.